
hadoop生态系统图,深入解析Hadoop生态系统图
时间:2024-12-10 来源:网络 人气:
深入解析Hadoop生态系统图

随着大数据时代的到来,Hadoop作为一款开源的分布式计算框架,已经成为处理海量数据的重要工具。Hadoop生态系统丰富多样,涵盖了从数据存储、处理到分析等多个层面。本文将为您详细解析Hadoop生态系统图,帮助您更好地理解Hadoop及其周边技术。
一、Hadoop生态系统概述

Hadoop生态系统由多个组件构成,这些组件协同工作,共同实现大数据的存储、处理和分析。以下是Hadoop生态系统中的一些关键组件:
二、Hadoop核心组件
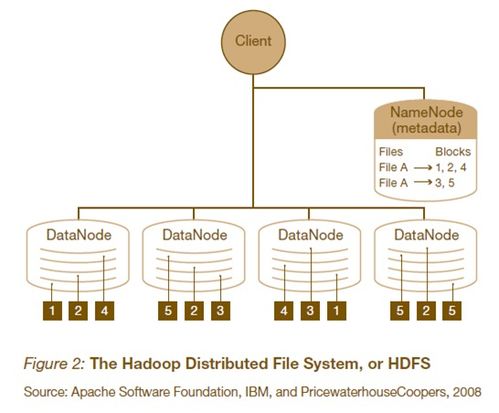
1. HDFS(Hadoop Distributed File System)
HDFS是Hadoop的分布式文件系统,负责存储海量数据。它采用主从架构,包括NameNode和DataNode。NameNode负责管理文件系统的命名空间,维护文件和目录的元数据;DataNode负责实际的数据存储和读写操作。
2. MapReduce
MapReduce是Hadoop的核心计算模型,用于处理大规模数据。它将任务分解成小的子任务,并分发到集群中进行处理。MapReduce主要由Map和Reduce两个阶段组成,Map阶段对数据进行初步处理,生成键-值对形式的中间结果;Reduce阶段对中间结果进行规约,得到最终结果。
3. YARN(Yet Another Resource Negotiator)
YARN是Hadoop的资源管理器,负责管理集群的计算资源。它将资源分配给不同的应用程序,确保应用程序能够高效地运行。
三、Hadoop生态系统周边组件
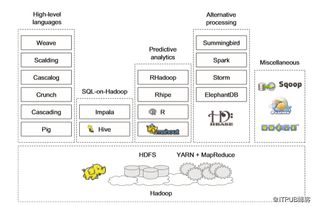
1. Hive
Hive是基于Hadoop的数据仓库,提供类似SQL的查询语言(HQL)。它可以将SQL查询转化为MapReduce任务,在Hadoop上执行。Hive适用于批量数据处理,但不适合实时查询。
2. Pig
Pig是一种高级数据流语言,用于简化Hadoop中的数据处理。Pig将数据转换成Pig Latin脚本,然后由Hadoop执行。Pig Latin是一种类似于SQL的数据流语言,可以方便地处理大规模数据。
3. HBase
HBase是一个分布式、可扩展的NoSQL数据库,基于HDFS构建。它适用于存储非结构化或半结构化数据,并支持实时读取和写入操作。
4. ZooKeeper
ZooKeeper是一个分布式协调服务,用于维护配置信息、命名空间、同步服务等功能。ZooKeeper在Hadoop集群中扮演着重要的角色,确保集群中的各个组件协同工作。
四、Hadoop生态系统图
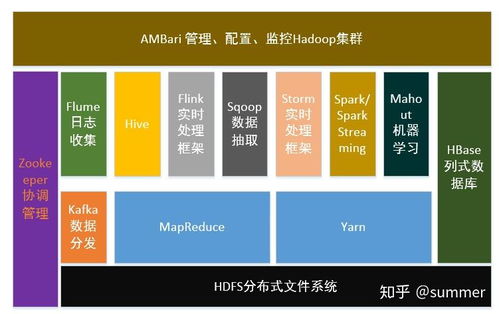
以下是一个简化的Hadoop生态系统图,展示了各个组件之间的关系:

Hadoop生态系统是一个庞大而复杂的体系,涵盖了从数据存储、处理到分析等多个层面。通过本文的解析,相信您对Hadoop生态系统有了更深入的了解。在实际应用中,可以根据需求选择合适的组件,构建适合自己的大数据解决方案。
相关推荐



教程资讯
教程资讯排行









